Basic Matrix Convolution Implementation Suite
With Benchmarking Tools
Table of Contents
- Matrix Convolution
- Benchmarking
- Algorithm
- Benchmarking Algorithms
- void conv4d_convolve_serial_naive();
- void conv4d_convolve_serial_discrete();
- void conv4d_convolve_serial_tiled(int block_size);
- void conv4d_convolve_threads_discrete();
- void conv4d_convolve_threads_tiled(int block_size);
- void conv4d_convolve_OpenMP_discrete();
- void conv4d_convolve_OpenMP_tiled(int block_size);
- void conv4d_convolve_CUDA_discrete(int block_size, int grid_size);
- void conv4d_convolve_CUDA_discrete_rewrite_gpu_data(int block_size, int grid_size);
- Benchmarking Framework
- Benchmarking Build Procedure
- Results
- Conclusions
Matrix Convolution
Introduction
Convolution is an operation involving two matrices: the image and the kernel. During this operation, elements in the convolved matrix are the sum of all nearby values in the image matrix weighted by the kernel. Usually, the kernel matrix is significantly smaller than the image.
To demonstrate the process of convolution, I’ll convolve two small, 1-dimensional matrices in the following figures. The input matrix (green) is [3,1,4,1,5,9,2], and the filter (red) [1,2,-1].
To get the first output of the matrix, add all the surrounding elements in the corresponding input array, weighted by the kernel.
Element 1: 
Note that the output matrix must be shifted to the right, so its corresponding element in the input matrix has neighbors in both directions.
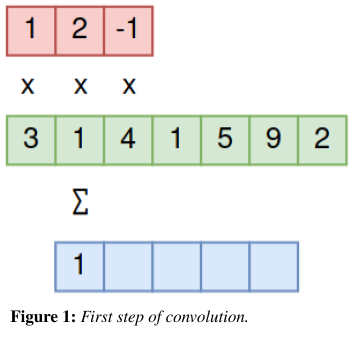
The process is repeated for each element in the output matrix by sliding the filter over the input image.
Element 2: 
Element 3: 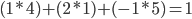
Element 4: 
Element 5: 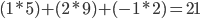


Aplications
Two common uses for matrix convolution are in image processing and artificial intelligence. Both of these applications are described in the sections below:
Image Processing
Many common image filters use matrix convolution. They do so by converting the image into a 3D matrix (width, height, channels, explained in greater detail in the next section)
A small filter (also known as a kernel) is slid across an image to produce an output image. Cleverly constructed filters can blur and sharpen the image, find corners and edges, and more.
Artificial Intelligence
Matrix convolution allows efficient implementations of neural network approximations. Each neuron is an element in a matrix. Convolving the matrix simulates the synapses between neurons. The filter represents the sensitivity of each simulated synapse. By adjusting the values in the filter, each synapse’s sensitivity changes, affecting the output from the neural network. Software like TensorFlow contain programs that update these filters, a process known as training.
Benchmarking
Algorithm
The process of convolution in this benchmark is an extension of the example in the previous section in a few ways. These extensions were included in the benchmark to increase parallelism complexity for the final project and to support common features in convolutional neural networks.
-
Convolution occurs in three dimensions. 3D convolution is natural for image processing because each image has three dimensions: width, height, and the number of channels. Figure 6 gives an example of the matrices’ structures and the variables used in the explanation and implementation of the algorithms. These variables are as follows:
- W, H: The input image’s width and height
- C: The number of channels in the input image. For example, many images have three color channels: red, green, and blue. Sometimes, there is an additional channel for transparency or alpha.
- R, S: The filter’s width and height
- P, Q: The output’s width and height
- M: The number of channels in the output.
- N (not shown): The number of input images that need to be applied by the filter. Assumed to be 1 in the diagram.
- U (not shown): The stride length, i.e. how much the kernel slides across the input matrix. In figures 1-3, the stride length is 1 because the filter shifts to the right by one element each time an element in the output is calculated.
The diagram below highlights the cells in each matrix that are used during the first operation.
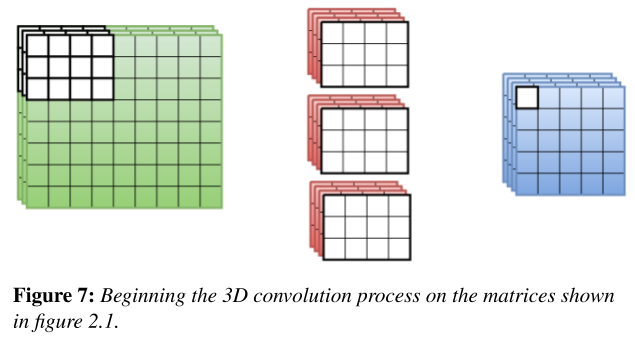
- At the end of the convolution operation, the result of the convolution operation is incremented by a vector, called “bias.” This vector is used predominantly in convolutional neural networks as another way to fine-tune them.
- After the bias was added, a function is applied to each element in the output matrix. This function is called the Rectified Linear Unit, and its function is
 if x<0 and
if x<0 and 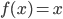 when x≥0.
when x≥0.
Because this convolution algorithm is targeted towards convolutional neural networks, terminology related to neural networks will be used in the program and explanation. For example, “input matrix” becomes “input feature map,” “filter” or “kernel” can become “weights,” etc.
Pseudocode
convolve(I, W, B, O):
Parameters:
I: the input feature map, a four dimensional array with dimensions [N][S+Q\*U][R+S\*U][C]
W: the weights, a four dimensional array with dimensions [S][R][C][M]
B: the bias, a one dimensional array with dimension [M]
Returns:
O: the output feature map, a four dimensional array with dimensions [N][Q][P][M]
Reset O so that each element is 0
For each n in N:
For each q in Q:
For each p in P:
For each m in M:
For each s in S:
For each r in R:
For each c in C:
Increase O[n][q][p][m] by I[n][q*U+s][p*U+r] * W[s][r][c][m]
Increase O[n][q][p][m] by B[m] (Bias)
O[n][q][p][m] = f(O[n][q][p][m]) (Apply the activation function)
Benchmarking Algorithms
The benchmarking framework contains nine variations of the convolution algorithm described in the previous section, described below:
void conv4d_convolve_serial_naive();
This algorithm convolves the input feature map by following the pseudocode verbatim, ignoring the machine’s hardware.
void conv4d_convolve_serial_discrete();
This algorithm improves in performance because it splits the loops for convolution and bias, giving the compiler more flexibility to perform its assembly-level optimizations.
void conv4d_convolve_serial_tiled(int block_size);
This algorithm attempts to further improve the performance by tiling the arrays, theoretically increasing cache hits.
void conv4d_convolve_threads_discrete();
This algorithm is similar to conv4d_convolve_serial_discrete, except that the output feature map’s rows are distributed among threads using the Pthread library.
void conv4d_convolve_threads_tiled(int block_size);
This algorithm is similar to conv4d_convolve_serial_tiled, except that the output feature map’s rows are distributed among threads using the Pthread library.
void conv4d_convolve_OpenMP_discrete();
This algorithm is similar to conv4d_convolve_serial_naive, except that it uses OpenMP to distribute the workload between threads. Each element in the output feature map is its own task and is run in parallel with other elements.
It was based off of the naive version because the discrete version created a race condition.
void conv4d_convolve_OpenMP_tiled(int block_size);
This algorithm is similar to conv4d_convolve_serial_tiled, except that it uses OpenMP to distribute the workload between threads. Each element in the output feature map is its own task and is run in parallel with other elements.
However, instead of tiling over q and p, tiling is performed over c so that the first three for loops can be collapsed. Again, this also helps remove the race condition, avoiding the need of a critical region.
void conv4d_convolve_CUDA_discrete(int block_size, int grid_size);
This algorithm is similar to conv4d_convolve_serial_discrete, except that it uses CUDA to distribute the workload between threads on the GPU. Each element in the output feature map is its own task and is run in parallel with other elements. Blocking happens naturally due to Nvidia GPUs’ architectures.
void conv4d_convolve_CUDA_discrete_rewrite_gpu_data(int block_size, int grid_size);
This algorithm is conv4d_convolve_CUDA_discrete, except that its memory policy is a bit different.
The CUDA functions use their own global, device-specific memory. To convolve a matrix in CPU memory with CUDA, this program copies that matrix and the filter over to the device memory. Then a GPU kernel can run on the GPU memory. Finally, after the kernel completes, the output matrix (in GPU memory) is copied back to the CPU.
This function copies the input feature map and layer from the CPU memory into the GPU before running conv4d_convolve_CUDA_discrete, costing time.
Benchmarking Framework
In addition to all nine functions, the benchmarking framework also contains tools to profile each algorithm and verify its correctness.
File Structure
The project contains seven files:
- CMakeLists.txt: A file used by CMake to build the project. It automatically disables benchmarks that aren’t supported by the machine.
- conv4D_data_structures.h: Definitions of feature maps and functions that aid in the benchmarking process.
- conv4D_data_structures.c: Implementation for functions in conv4D_data_structures.h.
- conv4D_impl.h: Definitions of the benchmarking algorithms in the previous section.
- conv4D_impl_CPU.c: Implementations of the benchmark that predominantly use the CPU (serial, OpenMP, and threads)
- conv4D_impl_GPU.cu: Implementations of the benchmark that predominantly use the GPU (CUDA)
- main.c: the main() function that benchmarks each algorithm with a macro called BENCHMARK_ALGORITHM. The marco times the execution of an algorithm, calculates its average error, and prints the following information on one line, separated by a comma and a tab:
- Algorithm name
- Average execution time, not including the first trial. Lower values indicate higher performance.
- The average difference between the output and the expected output per unit. Lower values indicate higher accuracy.
- Parameters in the function, if any.
All files are placed in the folder src/10_Convolution_Benchmark.
Data Structures
The convolutional layer and each feature map have their own data type and are stored in global memory. They’re defined in conv4D_data_structures.h.
Benchmarking Build Procedure
Process
Step 1: Download a copy of the full project from the GitHub repository: https://github.com/m516/CV-Sandbox
Step 2: In the root directory of the repository, run the following command:
cmake .
Step 3: Build the tool with make if you’re using Linux or Mac:
$ make 10_CONVOLUTION_BENCHMARK
Step 4: Run the program (contained in the bin subdirectory of the project folder)
$ bin/10_CONVOLUTION_BENCHMARK
Hardware Used for Benchmarking
I used a Lenovo Yoga 730 to perform benchmarking. It has the following hardware components:
- CPU: Intel Core i7-8550U
- Base clock: 1.80GHz
- Max. clock: 4 GHz
- Cache:
- L1 data: 128 kB
- L1 instruction: 128 kB
- L2: 1 MB
- L3: 8 MB
- Cores: 4
- Threads: 8
- NUMA nodes: 8
- RAM: 16 GB DDR4, 2400MHz
- GPU: Nvidia GTX 1050 Mobile
- Clock: 33MHz
- 4 GB dedicated RAM
The benchmark attempts to use as many resources as possible. OpenMP and Pthread implementations both take all 8 hardware threads.
Software Used for Benchmarking
- Operating system: agnostic (benchmarked with Ubuntu 20.04)
- Language: C
- Compiler: agnostic (benchmarked with GCC 9.3.0)
- Build tool: CMake
- Additional packages and libraries:
- OpenMP
- CUDA
- PThread
Results
TinyImageNet Neural Network Layer
The first benchmark is based on an intermediate feature map that was extracted from a TinyImageNet neural network running on Tensorflow. The extracted feature map and convolutional layer data were placed in binary files under the media/dnn directory in the project folder. To ensure that all algorithms work as expected, the output feature map was also extracted into a file, and the values in the calculated feature map are compared with the corresponding values in the file.
These are the dimensions of the input feature map:
- Input feature map filename: “dnn/Test_Input0/layer_0_output.bin”
- Layer weights filename: “dnn/Test_Input0/conv2_weights.bin”
- Layer bias filename: “dnn/Test_Input0/conv2_biases.bin”
- Input feature map filename: “dnn/Test_Input0/layer_1_output.bin”
- Batch size: 1
- Input feature map: 60x60x32
- Layer: 5x5x32
- Stride length: 1
Here is the time required to compute each algorithm with this data (highest performing algorithm in bold):
|
Algorithm |
Average Execution Time (s) |
Error per Element in Output Feature Map |
Speedup from serial_naive |
Speedup from serial_discrete |
GFLOPS |
|
serial_naive |
0.0858 |
0 |
1.00 |
0.09 |
1.87 |
|
serial_discrete |
0.0080 |
0 |
10.77 |
1.00 |
20.16 |
|
serial_tiled |
0.0550 |
0 |
1.56 |
0.14 |
2.92 |
|
threads_discrete |
0.0039 |
0 |
22.19 |
2.06 |
41.52 |
|
threads_tiled |
0.0035 |
0 |
24.60 |
2.28 |
46.03 |
|
OpenMP_discrete |
0.0022 |
0 |
38.18 |
3.54 |
71.43 |
|
OpenMP_tiled |
0.0170 |
0 |
5.06 |
0.47 |
9.46 |
|
cuda_discrete |
0.0369 |
0 |
2.32 |
0.22 |
4.35 |
According to this table, OpenMP and threading both significantly speed up the convolution program when used effectively, but OpenMP was more effective.
Tiled Performance
Most implementations of tiled convolution had worse performance than their discrete counterparts. When GCC optimized the for loops, it tried to distribute the instructions to minimize cache misses. It was able to optimize the chain of for loops very well, and it automatically vectorized operations with SIMD. My tiling interfered with many of those optimizations, reducing the overall performance of the algorithm.
In other words, GCC was much better at optimizing the loops for my machine than I was. Boy, I still have a lot to learn!
However, tiled convolution performed better than discrete convolution on Pthreads. I believe this is because the DRAM bandwidth imposes a bottleneck on this program, and tiling gave the program the opportunity to use data in the cache multiple times. That would explain the spike that occurs when block size is 6.



OpenMP Performance
Auto, static, and guided scheduling methods all performed about the same on this benchmark, and dynamic scheduling took significantly longer than the other three. That is expected with this algorithm because every task takes almost the same amount of time, since conditional branching is minimal.

I was unable to use Allinea or MAP because I don’t have the programs on my machine. I was able to profile the CUDA algorithms because the CUDA development kit came with its own tool: nvprof.
CUDA Performance
CUDA did not perform very well, but that’s likely because I don’t have much experience in the language or framework. However, the algorithm was parallelizable since latency generally decreased when grid_size and block_size increases.

Profiling
Below is the output from profiling the discrete CUDA algorithm with a block size of 4 and a grid size of 4.
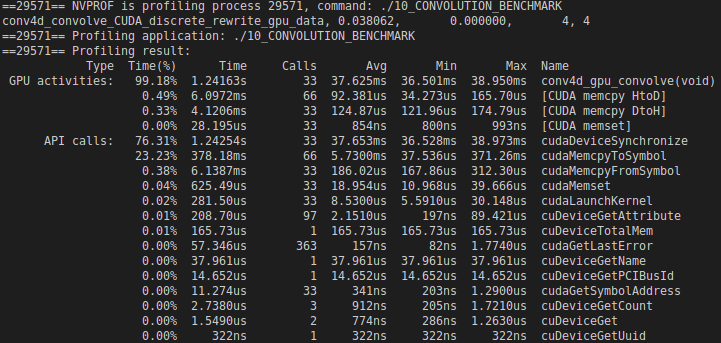
According to the tool, synchronizing all the data between the CPU and GPU memory took about 10 ms. Convolution took 120x longer on average than memory synchronization.
The average throughput was 2.17 FLOPS, and the peak theoretical performance is 1.8 TFLOPS (source: TechPowerUp). This suggests that my algorithm doesn’t efficiently use the hardware resources in the graphics card.
Conclusions
There is much room for improvement in all the algorithms that were benchmarked in this project.
Memory is a bottleneck for these algorithms because discrete convolution doesn’t allow stride-1 array accesses to all matrices. In this project, I haven’t covered at least two advanced optimization techniques that can dramatically improve memory access times by maximizing or enforcing stride-1 array accesses and data reuse.
Toeplitz Matrices
Matrix convolution can be transformed into matrix multiplication by converting one of the matrices into its Toeplitz matrix (source: Wikipedia). An additional latency is incurred by the conversion process, but the benefit of enforcing higher amounts of stride-1 array accesses would outweigh the cost of that latency in sufficiently large matrices.
Fourier Transform
Convolutions of large matrices are usually implemented most quickly using the Fourier transform (source: ccrma.stanford.edu) because only element-wise multiplication is necessary in the Fourier transform domain. In other words, it’s possible to take the Fourier transform of both, perform element-wise multiplication, then perform the inverse Fourier transform to convolve two matrices (http://pillowlab.princeton.edu).